“MongoDB的标准发行版本中提供了mongo shell。它提供了一种具有对JavaScript语言和标准函数的完全访问权限的JavaScript环境。它为MongoDB数据库提供了一个完整接口。”
在本章中,将学习mongo shell的基础知识以及如何使用它来管理MongoDB文档。在你深入探究创建与数据库交互的应用程序之前,理解MongoDB shell如何工作是很重要的。
没有比上手使用MongoDBshell更好的体验MongoDB数据库的方法了。我们将MongoDB shell介绍分成三个部分,以便读者能够更加容易地领会和实践这些概念。
第一节涵盖了数据库的基础功能,其中包括基本的CRUD操作符。接下来的一节将介绍高级的查询。本章的最后一节会阐释存储和检索数据的两种方式:嵌入和引用。
基本查询
本节将简要探讨CRUD操作符(创建、读取、更新和删除)。使用基础示例和练习,将学习这些操作在MongoDB中是如何执行的。另外,将理解查询是如何在MongoDB中执行的。
与用于查询的传统SQL相反,MongoDB使用了其自己的类似于JSON的查询语言来从存储数据中检索信息。
在成功安装MongoDB之后,将导航到目录F:\mongodb\bin\。这个文件夹具有用于运行MongoDB的所有可执行程序。
可以通过执行mongo可执行程序来启动MongoDB shell。
第一步总是要启动数据库服务器。打开命令行提示符(以管理员身份运行它)并且运行命令CD\。
接下来,运行命令F:\mongodb\bin\mongod.exe。(如果该安装位于其他某个文件夹,那么这个路径将相应变更。对于本章中的示例来说,安装位于F:\mongodb文件夹)。这样就会启动数据库服务器。
MongoDB会默认侦听本地主机接口的27017端口上所有的入站连接。
数据库服务器已经启动了,那么你就可以开始使用mongo shell将命令发送到该服务器。
在你查看mongo shell之前,我们简要了解如何使用导入/导出工具来将数据导入和导出MongoDB数据库。
首先,创建一个CSV文件来保存具有以下结构的学生记录:
接下来,将数据从MongoDB数据库导入到一个新的集合,以便了解该导入工具如何工作。
以管理员身份打开命令行提示符来运行它。以下命令被用于获得关于导入命令的帮助:
运行以下命令来将数据从exporteg.csv文件导入到MyDB数据库中一个新的名称为importeg的集合中:
1 | mongoimport.exe --host localhost --db mydb --collection importeg --type csv --file F:\MongoDB\zufang.csv --headerline |

第一条是上传失败的返回详情见mongodb导入csv报错 | zl的个人博客 (llz-github.github.io),第二条是上传成功的返回。
为了验证该集合是否被创建以及数据是否被导入,要使用mongo shell连接到该数据库(在本示例中是本地主机),并且你要运行命令来验证该集合是否存在。
要启动mongo shell,需要以管理员身份运行命令行提示符并且输入命令F:\MongoDB\bin\mongo.exe(该路径将因安装文件夹而异;在这个示例中,该文件夹是F:\sMongoDB),然后按下Enter键。
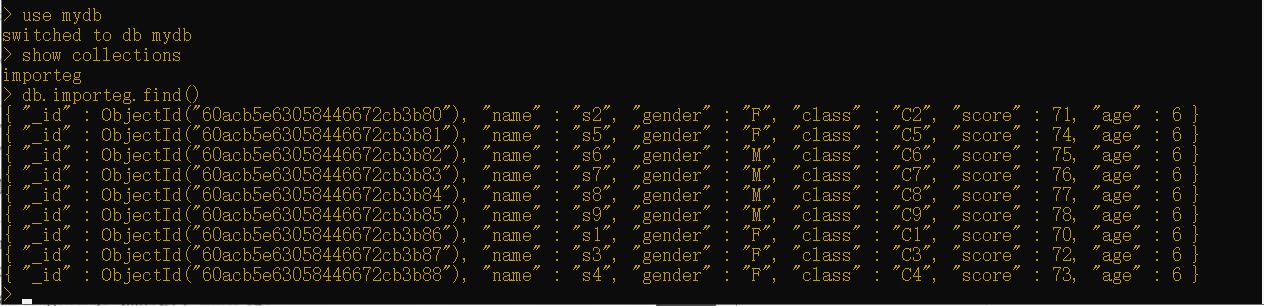
简要来说,此处你正在做的就是:
(1)连接到mongo shell。
(2)切换到你的数据库,本示例中是MyDB。
(3)使用show collections检查存在于MyDB数据库中的集合。
(4)使用导入工具检查你导入的集合数量。
(5)最后,执行find()命令来检查新集合中的数据。
要连接到不同的主机和端口,可以将-host和-port与命令一起使用。默认情况下数据库test被用于上下文环境。在任何时候,执行db命令都会显示当前shell连接的数据库:
为了显示所有的数据库名称,可以运行show dbs命令。执行这个命令将列出用于所连接服务器的所有数据库。
在任何时候,都可以使用help)命令来获得帮助。
如果需要关于db或collection的任何方法的帮助,则可以使用db.help()或db.<CollectionName>.help()。
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
我们现在开始探究MongoDB中用于查询的选项。切换到mydb1数据库。
这样就会将上下文切换到mydb1。使用db命令可以确认这一点。
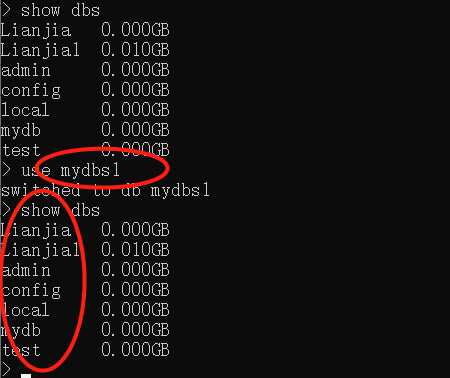
尽管上下文被切换到了mydb1,但如果运行show dbs命令,也不会显示该数据库名称,因为MongoDB只有在将数据插入到数据库时才会创建该数据库。这与MongoDB用于数据助益、动态命名空间分配以及简化和加速的开发过程的动态方式是一致的。如果此时运行show dbs命令,那么将不会在数据库列表中列出mydb1数据库,因为该数据库只有在数据被插入时才会被创建。
创建和插入
你现在要查看数据库和集合是如何被创建的。正如较早所阐释的,MongoDB中的文档都是JSON格式的。
现在将看到如何创建文档。
第一个文档遵循第一个原型,而第二个文档遵循第二个原型。你已经创建了两个名称为userl和user2的文档。
接着你要以下面的操作顺序将这两个文档(userl和user2)添加到users集合:
1 | user1 = {FName:"Test",LName:"User",Age:30,Gender:"M",country:"US"} |
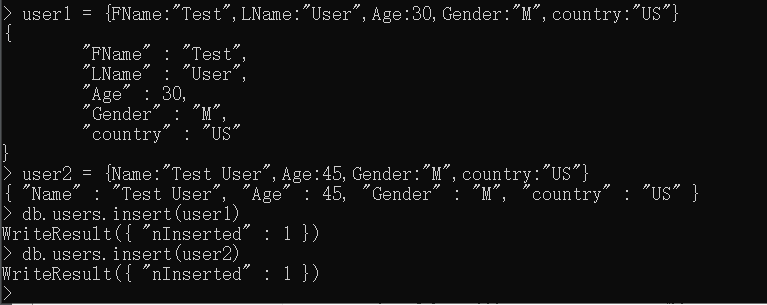
上述操作不仅会将这两个文档插入到users集合,还会创建该集合以及数据库。可以使用show collections和show dbs命令来验证这一点。
正如前面所提到过的,show dbs将显示数据库列表。
而show collections将显示当前数据库中的集合列表。
执行命令db.users.find)将显示users集合中的文档。

可以看到所创建的两个文档都显示出来了。除了你添加到文档的字段以外,还会为所有文档生成一个附加的_id字段。
所有的文档都必须具有一个唯一的_id字段。如果没有显式指定,那么MongoDB同样会自动分配一个作为唯一对象ID,就像上面的示例中所显示的那样。
你没有显式插入一个id字段,但当使用find()命令来显示文档时,可以看到一个与每个文档相关联的id字段。
其背后的原因在于,默认情况下索引是被创建在该id字段上的。
可以使用ensurelndex()和droplIndex()命令将索引添加到集合中或者从中移除。在本章后面的内容中我们将介绍这一点。默认情况下,索引会被创建在所有集合的_id字段上。这一默认索引无法被删除。
显式创建集合
在上面的示例中,第一个插入操作隐式地创建了集合。不过,用户也可以在执行插入语句之前显式创建一个集合。
1 | db.createCollection("users") |
使用循环插入文档
也可以使用一个for循环来将文档添加到集合。以下代码使用了for来插入用户。
1 | for(var i=1; i <= 20; i++) db.users.insert({"Name":"Test User" + i, "Age":10 + i, "Gender": "F", "Country": "India"}) |
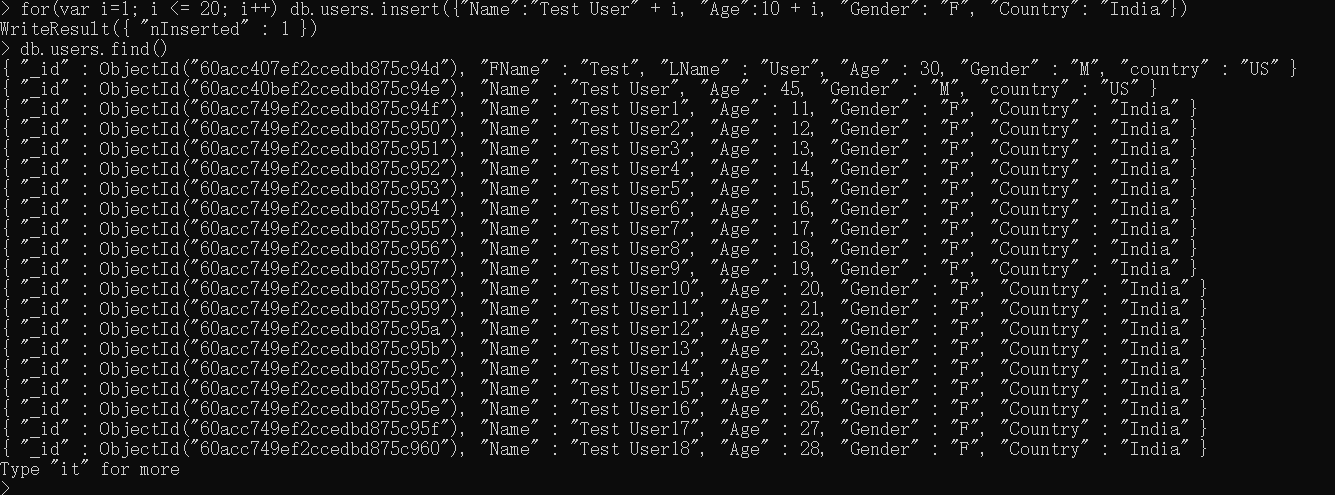
用户出现在集合中。在你继续学习之前,我们要理解“Type“it”for more”语句。
find命令会返回指向结果集的一个游标。相较于一次性在界面上显示所有文档(可能会有数千或数百万个结果),游标会显示前20个文档并且等待请求遍历(it)以便显示其后20个文档,以此类推,直到所有的结果集都被显示出来。
所产生的游标还可以被分配到一个变量,然后可以使用一个while循环编程式地遍历它。该游标对象还可以作为一个数组来操作。
在你的例子中,如果输入“it”并且按下Enter键,就会出现以下信息:

通过显式指定_id进行插入
在前面关于插入的示例中,并没有指定id字段,因此它是被隐式添加的。在以下示例中,将看到如何在一个集合中插入文档时显式指定id字段。
在显式指定id字段时,你必须注意该字段的唯一性;否则插入将会失败。
以下命令会显式指定id字段:
1 | db.users.insert({"_id":10,"Name":"explicit id"}) |

该插入操作会在users集合中创建以下文档:{“id”:10,”Name”:”explicit id”)这一点可以通过运行查询命令来确认。
更新
在本节中将探究update()命令,它被用于更新一个集合中的文档。
update()方法默认会更新单个文档。如果需要更新所有符合选择条件的文档,那么可以通过设置multi选项为true来实现这一目的。
我们首先更新已有列的值。$set操作符将被用于更新记录。
以下命令会将所有女性用户的年龄更新为100:
1 | db.importeg.update({"gender":"F"},{$set:{"age":100}}) |
要检查该更新是否完成,可以运行一个find命令来检查所有的女性用户。
1 | db.importeg.find({"gender":"F"}) |
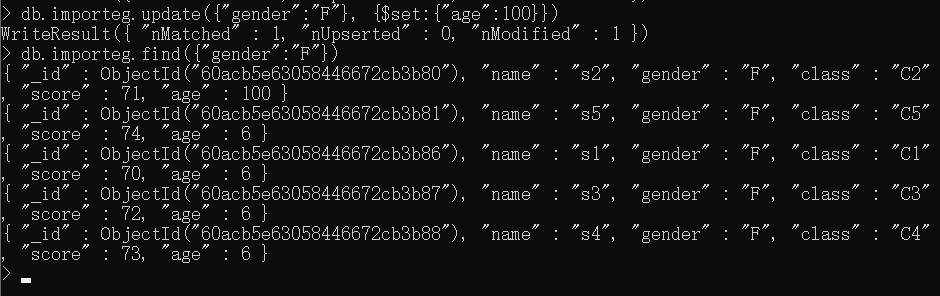
如果检查该输出结果,就会发现只更新了第一个文档记录,这是更新的默认行为,因为没有指定multi选项。现在我们修改该update命令并且加入multi选项:
1 | db.importeg.update({"gender":"F"},{$set:{"age":100}},{multi:true}) |
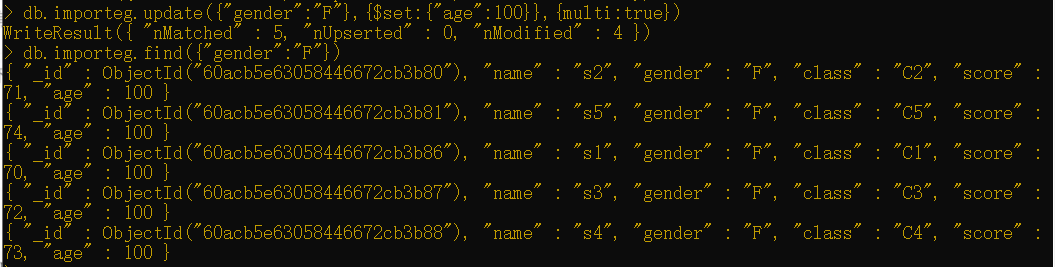
如你所见,已经将所有符合条件记录age更新为100。
在处理一个真实的应用程序时,你可能会碰到模式演化的情况,其中你可能最终会将字段添加到文档或者从中移除字段。我们来看看如何在MongoDB数据库中执行这些修改。
update()操作可被用于文档级别,这有助于更新一个集合中的单个文档或者文档集。
接下来,我们来看看如何将新字段添加到文档。为了将字段添加到文档,需要使用带有$set操作符和multi选项的update()命令。
如果用$set使用一个字段名称,而该字段不存在,那么这个字段将会被添加到文档。以下命令会将字段company添加到所有的文档:
1 | db.importeg.update({},{$set:{"company":"TEstComp"}},{multi:true}) |
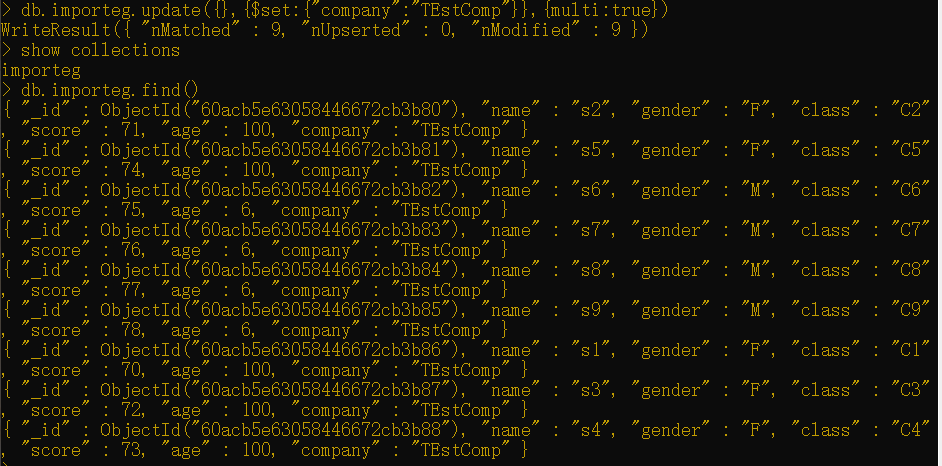
如果对已经存在于文档中的字段执行update()命令,那么将会更新该字段的值;不过,如果该字段并不存在于文档中,那么该字段将会被添加到文档。
接下来将看到如何使用带有Sunset操作符的相同update()命令来从文档中移除字段。
以下命令会将字段Company从所有的文档中移除:
1 | db.importeg.update({},{$unset:{"company":""}},{multi:true}) |
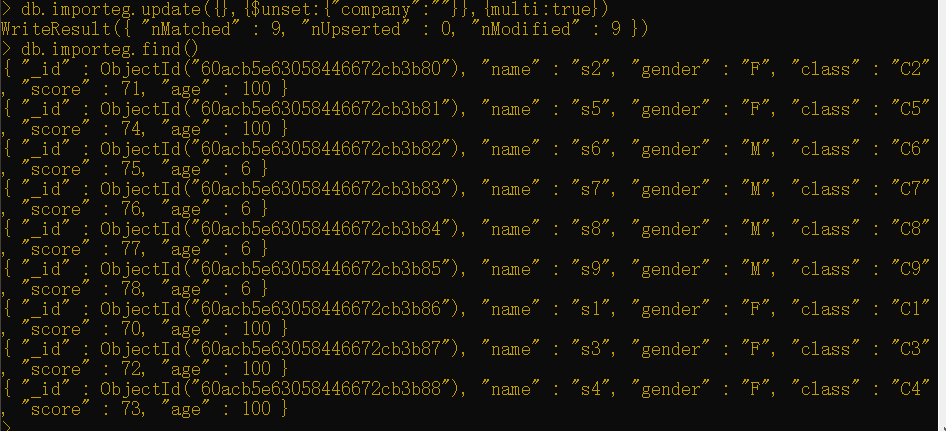
删除
要删除一个集合中的文档,可以使用remove()方法。如果指定一个选择条件,那么只有满足该条件的文档才会被删除。如果没有指定条件,则会删除所有的文档。
以下命令将会删除Gender=‘M’的文档:
1 | db.importeg.remove({"gender":"M"}) |
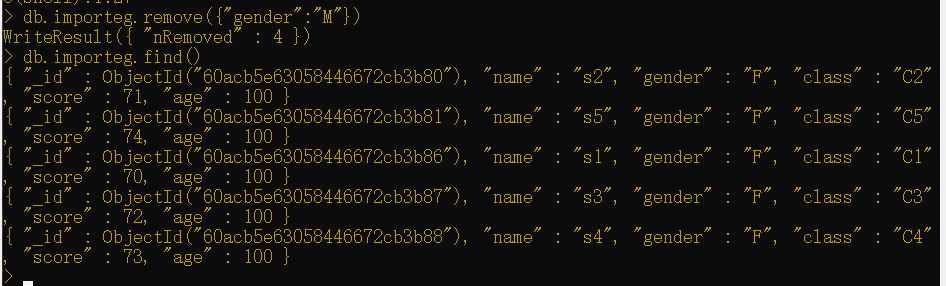
不会返回任何文档。
以下命令将删除所有的文档:
1 | db.importeg.remove({}) |
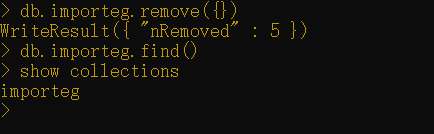
如你所见,不会返回任何文档。
最后,如果希望删除该集合,那么以下命令将会删除这个集合:
1 | db.importeg.drop() |
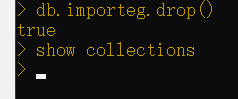
true为了验证该集合是否被删除,可以运行show collections命令。
如你所见,没有显示集合名称,这样就可以确认该集合已经从数据库中移除了。我们已经介绍了基本的创建、更新和删除操作,下一节将介绍如何执行读取操作。
读取
在本章的这一部分将了解各种示例,这些示例揭示了作为MongoDB的一部分当前可用的查询功能,这些功能使得你能够从数据库中读取所存储的数据。
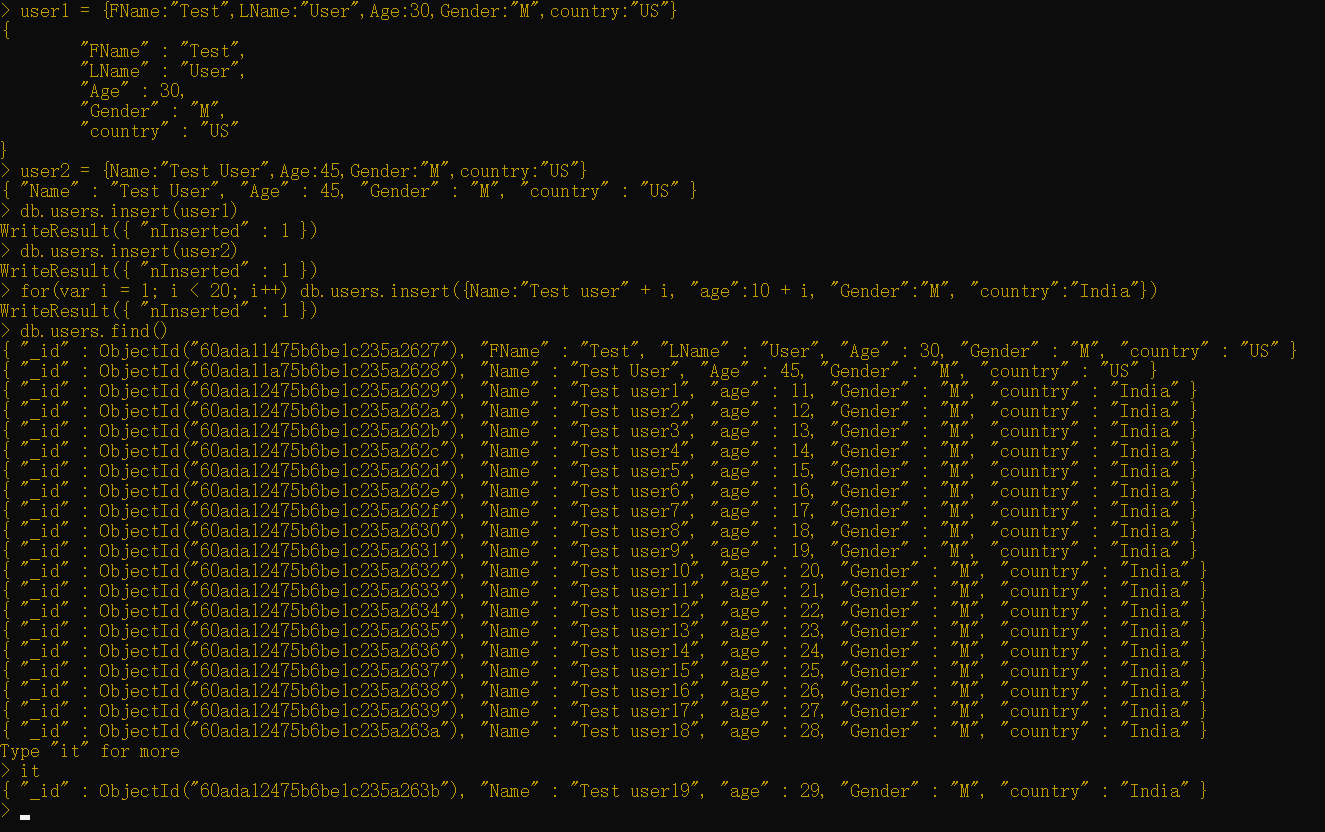
为了开始使用基本查询,首先创建users集合并且使用insert命令插入数据。
1 | user1 = {FName:"Test",LName:"User",Age:30,Gender:"M",country:"US"}user2 = {Name:"Test User",Age:45,Gender:"F",country:"US"}db.users.insert(user1)db.users.insert(user2)for(var i = 1; i < 20; i++) db.users.insert({Name:"Test user" + i, "Age":10 + i, "Gender":"M", "country":"India"}) |
查询文档
MongoDB提供了一个富查询系统。查询文档可以作为参数被传递到find)方法来过滤一个集合中的文档。
一个查询文档是在前“{”和后“}”一对大括号中指定的。一个查询文档是在返回结果集之前针对集合中的所有文档来匹配的。
使用不带有任何查询文档的find()命令或者带有一个空查询文档的像find({})这样的命令会返回集合中所有的文档。
一个查询文档可以包含选择器和投影器。
选择器就像SQL中的where条件或者一个用于过滤出结果的过滤器。
投影器就像选择条件或者用于显示数据字段的选择列表。
选择器
你现在将看到如何使用选择器。以下命令将返回所有的女性用户:
1 | db.users.find({"Gender":"M"}) |
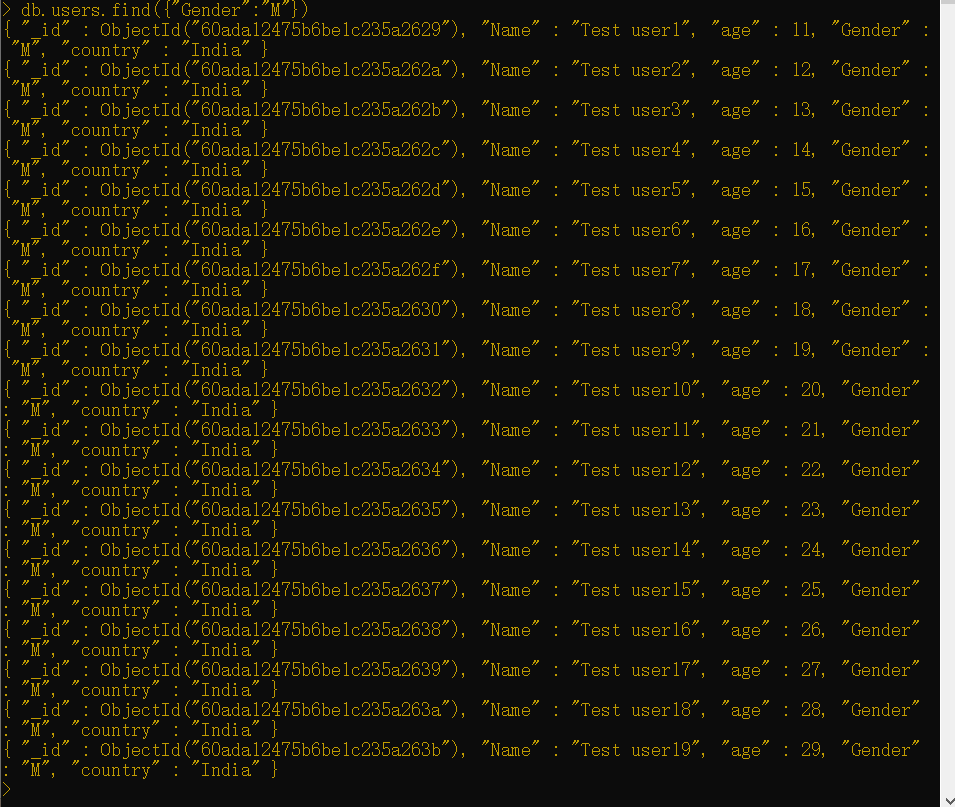
MongoDB还支持将不同条件合并到一起的操作符以便根据你的需求来改进你的搜索。
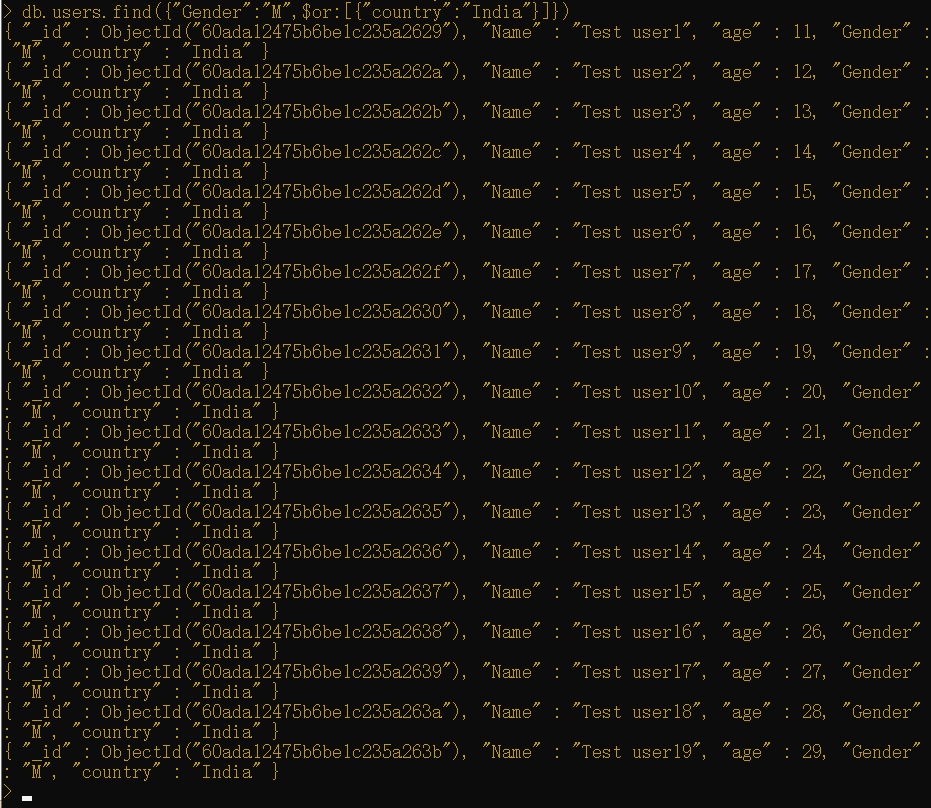
现在我们将上面的查询修改为查询来自印度的女性用户。以下命令将返回相同结果:
1 | db.users.find({"Gender":"M",$or:[{"country":"India"}]}) |
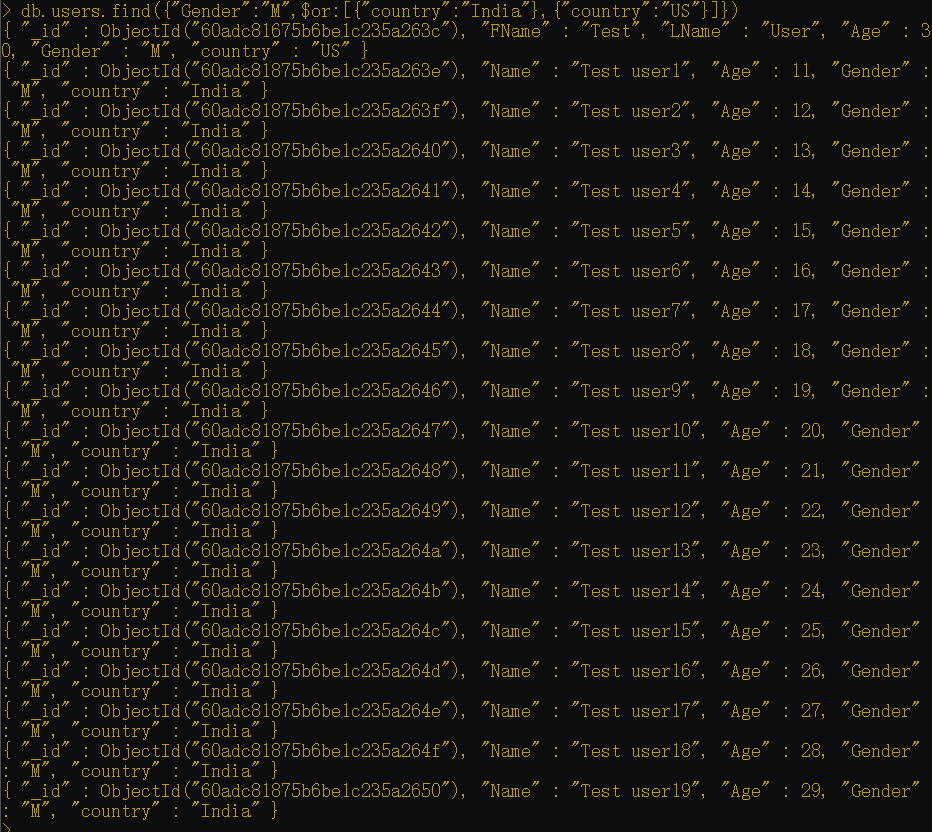
接下来,如果希望找出所有来自印度或美国的女性用户,则可以执行以下命令:
1 | db.users.find({"Gender":"M",$or:[{"country":"India"},{"country":"US"}]}) |
出于聚合的需要,则需要使用聚合函数。接着,将学习如何将count()函数用于聚合。
在上面的示例中,相较于显示文档,你希望计算出生活在印度或美国的女性用户数。因此要执行以下命令:
1 | db.users.find({"Gender":"M",$or:[{"country":"India"},{"country":"US"}]}).count() |
投影器
你已经看到了如何使用选择器来过滤出集合中的文档。在上面的示例中,find0命令会返回匹配该选择器的文档的所有字段。
我们来将一个投影器添加到该查询文档,其中,除了该选择器之外,你还将涉及需要被显示的具体细节或者字段。
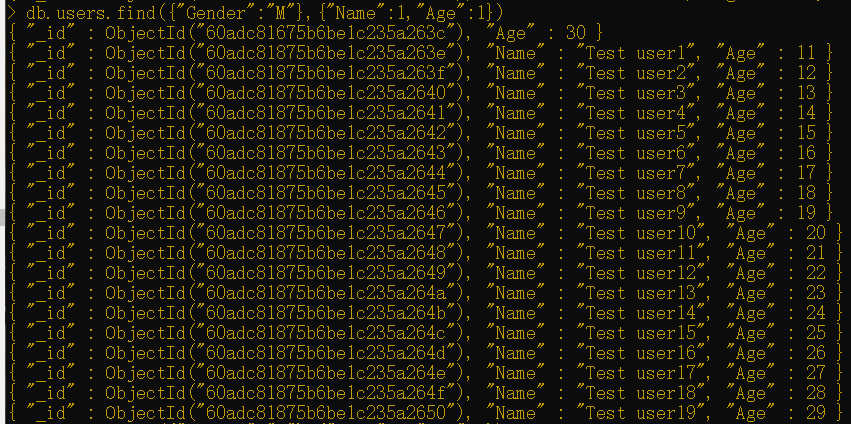
假定你希望显示所有女性员工的名字和年龄。在这种情况下,就还需要将一个投影器与该选择器一起使用。
执行以下命令以返回期望的结果集:(0不显示,1显示)
1 | db.users.find({"Gender":"M"},{"Name":1,"Age":1}) |
sort()
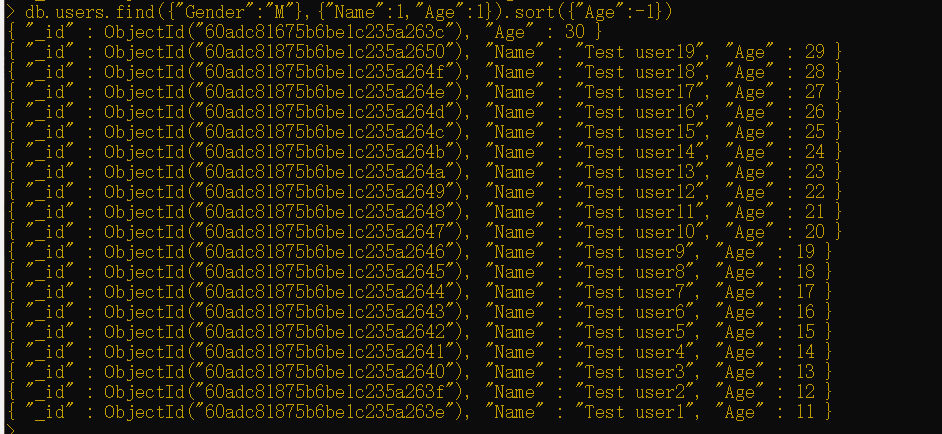
在MongoDB中,排列顺序是按如下来指定的:1用于升序排列,而-1用于降序排列。
如果在上面的示例中,你希望按照年龄降序排列记录,那么你就要执行以下命令:
1 | db.users.find({"Gender":"M"},{"Name":1,"Age":1}).sort({"Age":-1}) |
limit()
你现在将了解如何才能限制你的结果集中的记录。例如,在具有数千个文档的大型集合中,如果仅希望返回5个匹配的文档,则可以使用limit命令,它完全可以让你完成该任务。
回到之前对生活在印度或美国的女性用户的查询,假如你希望限制该结果集并且只返回两个用户,则需要执行以下命令:
1 | db.users.find({"Gender":"M",$or:[{"country":"India"},{"country":"US"}]}).limit(2) |

skip()
如果需求是跳过前两个记录并且返回第3和第4个用户,则可以使用skip命令。需要执行以下命令:
1 | db.users.find({"Gender":"M",$or:[{"country":"India"},{"country":"US"}]}).limit(2).skip(2) |

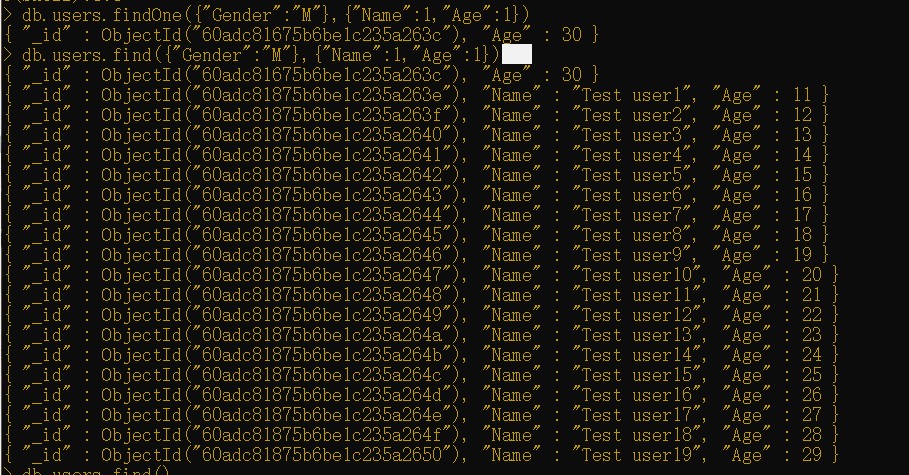
findOne()
findOne()命令类似于find()命令。findOne()方法可以使用与find()一样的参数,但不同于返回一个游标,它会返回单个文档。假设你希望返回一个要么生活在印度要么生活在美国的女性用户,可以使用以下命令来实现此目标:
1 | db.users.findOne({"Gender":"M"},{"Name":1,"Age":1}) |
使用游标
在使用了find()方法时,MongoDB会将查询结果作为一个游标对象来返回。为了显示该结果,mongo shell会遍历所返回的游标。
MongoDB使得用户可以使用find方法的游标对象。在接下来的示例中,将看到如何将游标对象存储到一个变量中并且使用while循环来操作它。
假设你希望返回在美国的所有用户。为了实现该目标,你创建了一个变量,将find()的输出结果指派给了这个变量,该结果是一个游标,然后使用while循环遍历和打印该输出结果。
这段代码看起来应该如下所示:
1 | var c = db.users.find("country":"US")while(c.hasNext()) printjson(c.next()) |
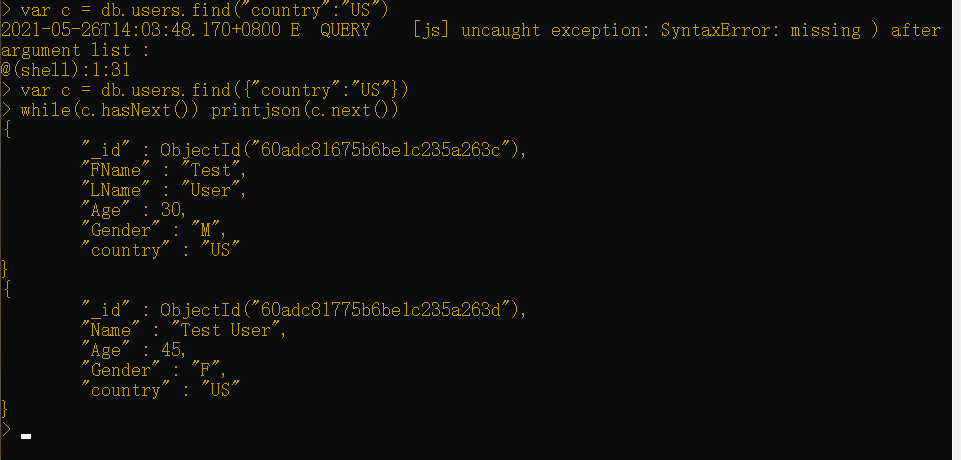
next()函数会返回下一个文档。hasNext()函数会在一个文档存在时返回true,而printjson()会以JSON格式呈现该输出结果。
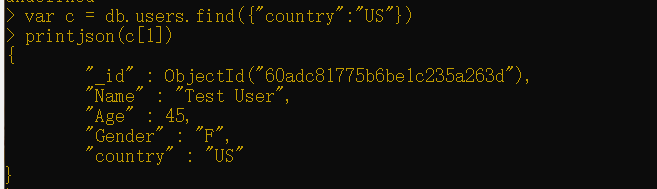
被分配给游标对象的变量还可以作为数组来操作。如果,相较于循环遍历该变量,你希望显示位于数组索引1的文档,则可以运行以下命令:
1 | var c = db.users.find({"country":"US"})printjson(c[1]) |
explain()
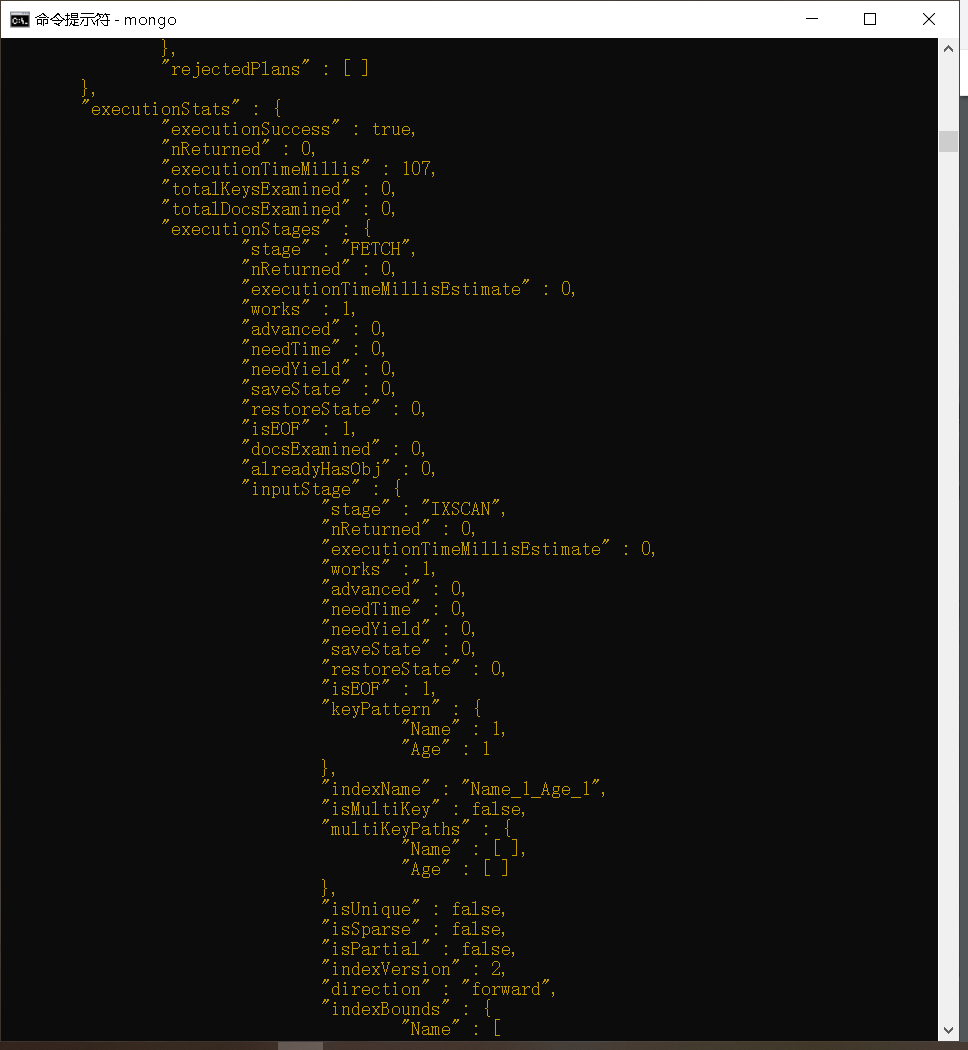
explain()函数可用于查看在执行一个查询时MongoDB数据库当前运行的步骤。从版本3.0开始,该函数的输出格式以及传递给该函数的参数已经发生了变化。它使用了一个可选的被称为verbose的参数,它会判定explain输出看起来应该是什么样。这些是详细级别的模式:allPlansExecution、executionStats 以及queryPlanner。默认的详细级别模式是queryPlanner,这意味着如果不做指定,则将默认为queryPlanner。
以下代码涵盖了过滤username字段时执行的步骤:
1 | db.users.find({"Name":"Test User"}).explain("allPlansExecution") |

如你所见,explain()输出结果会返回关于queryPlanner、executionStats和serverlnfo的信息。正如上面代码显示的,该输出所返回的信息取决于所选择详细程度的模式。
你已经看到了如何执行基本查询、排序、限制等。你还看到了如何使用while循环操作结果集或者将结果集作为数组来操作。在下一节中,将了解索引以及如何才能在你的查询中使用它们。
使用索引
索引被用于为频繁使用的查询提供高性能读取操作。默认情况下,当一个集合被创建并且文档被添加到其中时,就会在该文档的_id字段上创建一个索引。
在本节中,将了解如何创建不同类型的索引。我们首先使用for循环在一个名称为testindx的新集合中插入1百万个文档。
1 | for(var i=0; i <= 1000000; i++) {db.testIndex.insert({"Name":"user" + i, "Age":Math.floor(Math.random() * 120)})} |
接着,运行find()命令抓取值为user101的一个Name。运行explain()命令检查MongoDB正在执行哪些步骤以便返回结果集。
1 | db.testIndex1.find({"Name":"user101"}).explain("allPlansExecution") |
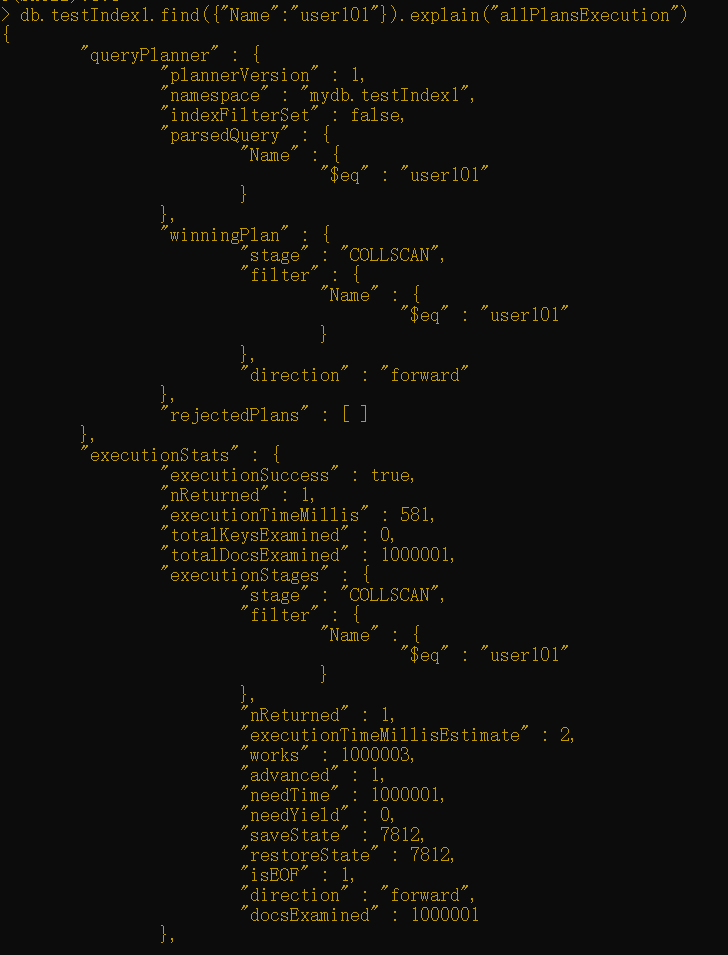
如你所见,数据库扫描了整个表。这会造成严重的性能影响并且是由于没有使用索引造成的。
单键索引
我们在该文档的Name字段上创建一个索引。使用ensurelndex()来创建这个索引。
1 | db.testIndex1.ensureIndex({"Name":1}) |

索引的创建需要几分钟的时间,这取决于服务器以及集合的大小。
我们来运行与你之前使用explainO运行的相同的查询,以检查在索引创建之后数据库会执行哪些步骤。检查输出结果中的n、nscanned和millis字段。
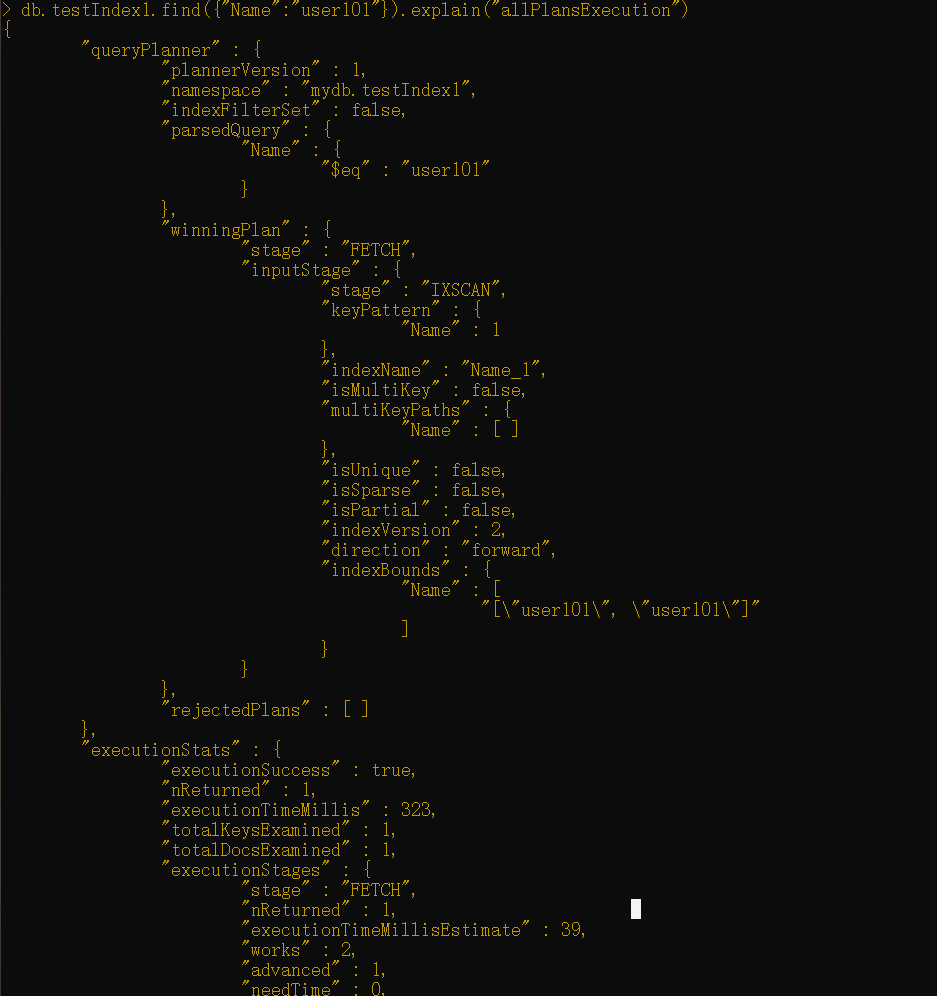
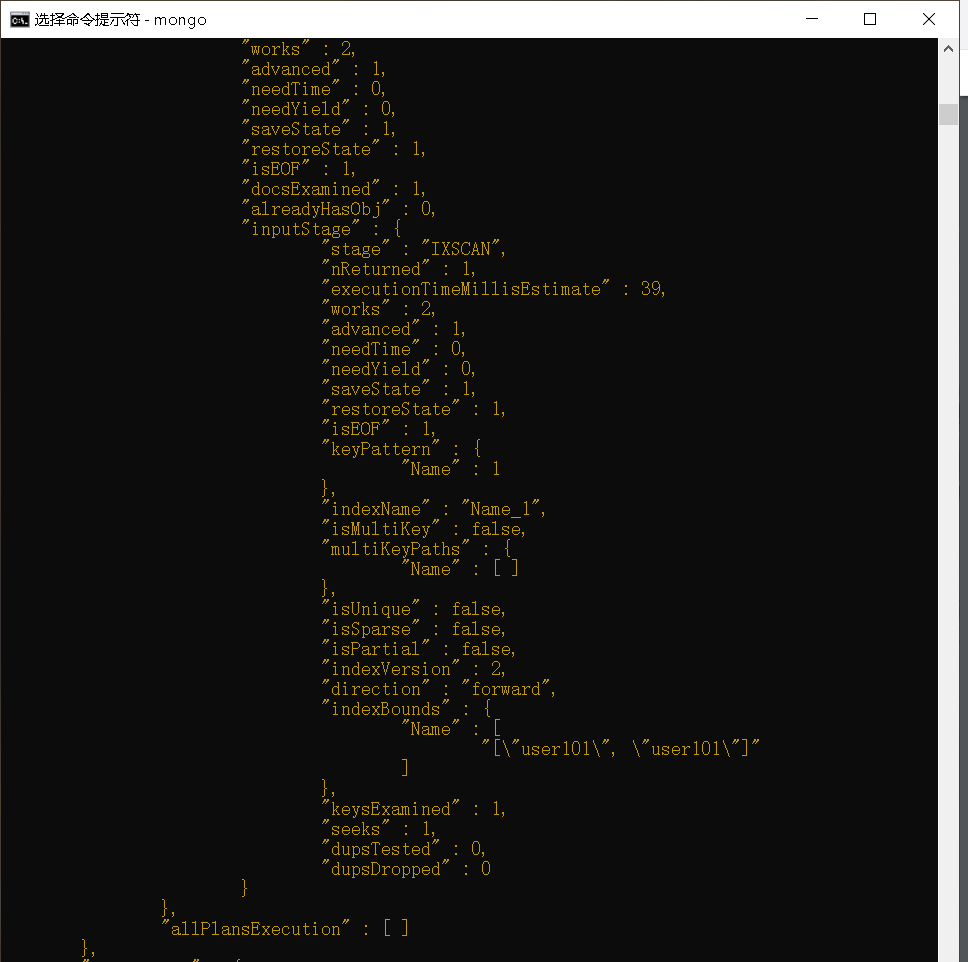
正如可以在该结果中所看到的,没有进行表扫描。索引的创建会在查询执行时间方面产生显著的差异。
复合索引
在创建一个索引时,你应该牢记,索引要覆盖你大多数的查询。如果有时仅查询Name字段并且有时同时查询Name和Age字段,那么在Name和Age字段上创建一个复合索引将会比在单一字段上创建索引更有益处,因为复合索引将覆盖这两种查询。
以下命令会在testindx集合的Name和Age字段上创建一个复合索引。
1 | db.testindex1.ensureIndex({"Name":1,"Age":1}) |
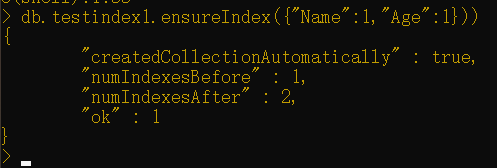
复合索引有助于MongoDB更有效地执行带有多个子句的查询。在创建一个复合索引时,还有一点非常重要,这就是要牢记字段将被用于第一个出现的精确匹配(比如Name:”S1”),其后是要用在范围中的字段(比如Age:{“$gt”:20})。
因此,上面的索引对于以下查询将很有帮助:
1 | db.testindex1.find({"Name":"user5","Age":{"$gt":25}}).explain("allPlansExecution") |
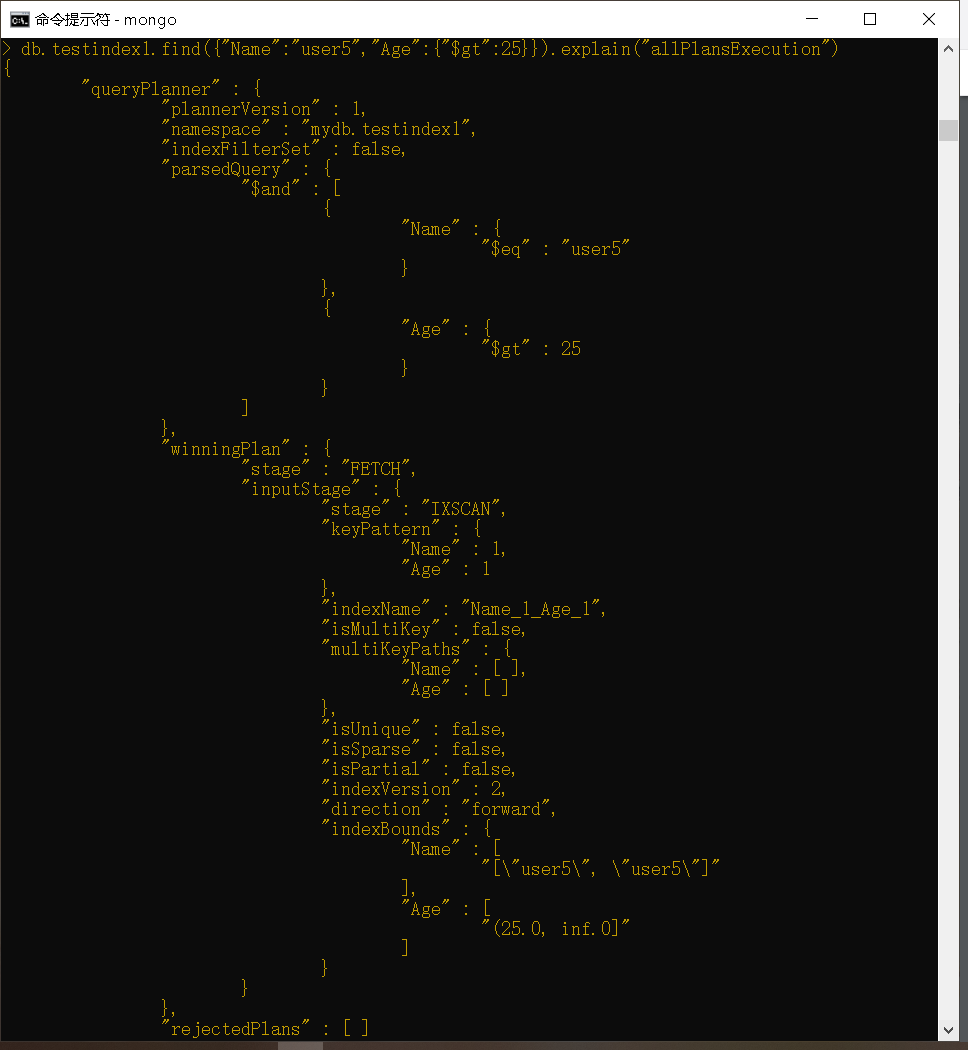
对sort操作的支持
在MongoDB中,使用一个索引字段来对文档排序的sort操作会提供最佳的性能。
就像在其他数据库中一样,由于这一点,MongoDB中的索引具有一个顺序。如果一个索引被用于访问文档,那么它将按照与索引相同的顺序来返回结果。
复合索引需要在对多个字段进行排序时创建。在一个复合索引中,输出结果可以按照索引前缀的顺序或者完整索引的顺序来排序。
索引前缀是复合索引的一个子集,它包含索引开头部分的一个或多个字段。
例如,{x:1,y:1,z:1}就是复合索引的索引前缀。
sort操作可以基于索引前缀的任意组合,比如{x:1},{x:1,y:1}。
如果一个复合索引是排序的一个前缀,那么它就仅能有助于排序。
例如,一个基于Age、Name和Class的复合索引,类似于
db.testindx.ensureIndex({“Age”:1,”Name”:1,”Class”:1})
那么,它对于以下查询就是有用的:
db.testindx.find().sort({“Age”:1})
db.testindx.find().sort({“Age”:1,”Name”:1})
db.testindx.find().sort({“Age”:1,”Name”:1,”Class”:1)}
上面的索引在以下查询中没什么用处:
db.testindx.find().sort({“Gender”:1,”Age”:1,”Name”:1})
可以通过使用explain()命令来诊断MongoDB是如何处理一个查询的。
唯一索引
在一个字段上创建索引并不会确保唯一性,因此,如果一个索引是基于Name字段创建的,那么两个或多个文档就可以具有相同的名称。不过,如果唯一性是需要被启用的其中一个约束,那么在创建该索引时,这个唯一属性就需要被设置为true。
首先,我们删除已有的索引。
1 | db.testIndex1.dropIndexes() |
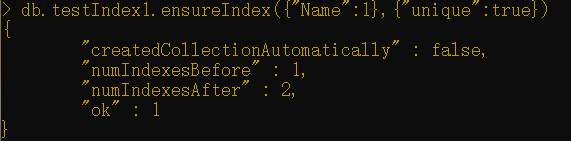
以下命令将在testindx集合的Name字段上创建一个唯一索引:
1 | db.testIndex1.ensureIndex({"Name":1},{"unique":true}) |
现在,如果像下面所示的那样尝试在该集合中插入重复的名称,那么MongoDB就会返回一个错误,并且不允许重复记录的插入:

如果检查该集合,就会看到只保存了第一个。
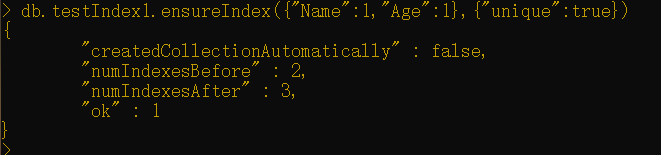
也可以为复合索引启用唯一性,这意味着尽管单个字段可以具有重复值,但其组合将一直是唯一的。
例如,如果有一个{“name”:1,“age”:1}的索引,
1 | db.testIndex1.ensureIndex({"Name":1,"Age":1},{"unique":true}) |
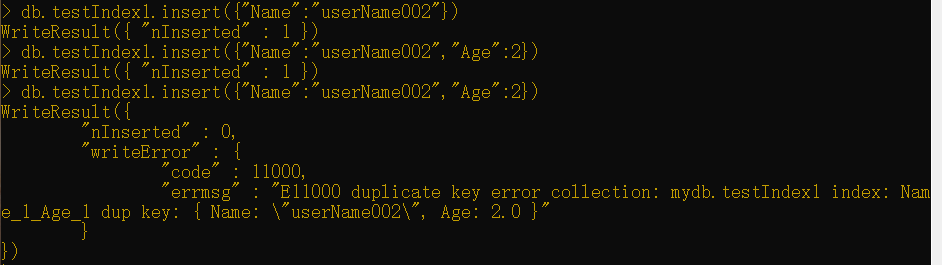
那么以下插入将是允许的:
1 | db.testIndex1.insert({"Name":"userName002"})db.testIndex1.insert({"Name":"userName002","Age":2}) |

不过,如果执行以下代码:
1 | db.testIndex1.insert({"Name":"userName002","Age":2}) |
它将抛出一个错误,如以下代码所示:
可以先创建集合并且插入文档,然后在该集合上创建一个索引。如果在该集合上创建一个唯一索引,而创建索引的字段可能存在重复值的话,那么索引的创建将会失败。
为了满足这一场景,MongoDB提供了一个dropDups选项。这个dropDups选项会保留找到的第一个文档并且移除具有重复值的所有后续文档。
此函数在3.0后已废弃
以下命令将在name字段上创建一个唯一索引,并且将删除所有重复的文档:
1 | db.testIndex1.ensureIndex({"Name":1},{"unique":true,"dropDups":true}) |
system.indexes
无论你何时创建一个数据库,默认情况下都会创建一个system.indexes集合。关于数据索引的所有信息都存储在system.indexes集合中。这是一个保留集合,因此你无法修改其文档或者从中移除文档。你只能通过ensurelndex和dropIndexes数据库命令来操作它。
无论何时创建了一个索引,都可以在system.indexes中看到其元信息。以下命令可用于提取所有关于示例集合的索引信息:
1 | db.collectionName.getIndexes() |
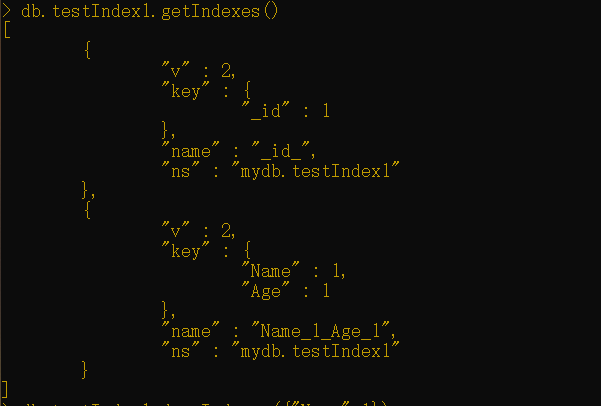
例如,以下命令将返回所有在testindx集合上创建的索引:
1 | db.testIndex1.getIndexes() |
dropIndex
dropIndex命令被用于移除索引。
以下命令将从testindx集合中移除Name字段索引:
1 | db.testIndex1.dropIndexes({"Name":1,"Age":1}) |

relndex
当已经在集合上执行了若干插入和删除时,你可能必须重构索引,以便可以用最佳的方式使用索引。relndex命令被用于重构索引。
以下命令会重构一个集合的所有索引。它首先会删除索引,其中包括_id字段上的默认索引,然后它会重构这些索引。
1 | db.collectionname.reIndex() |
我们将在下一章详尽探讨MongoDB中可用的不同类型的索引。
索引如何工作
MongoDB会在一个二叉树(BTree)结构中存储索引,因此它自动支持范围查询。
如果一个查询中使用了多个选择条件,那么MongoDB就会尝试找到最佳的单个索引来选择一个候选集。在那之后,它会依次遍历该集合来估算其他条件。
在首次执行该查询时,MongoDB会为每一个可用于该查询的索引创建多个执行计划。它会让这些计划在一定的时间间隔中轮流执行,直到执行最快的计划完成。然后其结果会被返回到系统,该结果会记住最快执行计划使用的索引。
对于后续查询,将会使用此被记住的索引,直到该集合中发生了一定数量的更新。在超过更新限制时,系统将再次执行该处理过程以找出此时适用的最佳索引。
当发生以下任意事件时,就会再次对查询计划进行评估:
- 集合接收到1000个写操作。
- 添加或删除了一个索引。
- mongod程序重启了。
- 发生了用于重构索引的再次索引。
如果希望重写MongoDB的默认索引选择,那么可以使用hint()方法达成目的。
在版本2.6中引入了索引过滤器。它是由优化器将为一个查询所评估的索引组成的,评估对象包括查询、投影和排序。MongoDB将使用由索引过滤器提供的索引并将忽略hin()。
在版本2.6之前,MongoDB一直都仅使用一个索引,因此你需要确保组合索引的存在,以更好匹配你的查询。这可以通过检查查询的排序以及搜索条件来完成。
索引交集是在版本2.6中引入的。它使得用于满足具有复合条件的查询的索引交集成为可能,其中一部分条件由一个索引满足,而其他部分则由其他索引来满足。
一般来说,索引交集是由两个索引组成的;不过,也可以将多个索引交集用于解决一个查询。此功能提供了更好的优化。
就像在其他数据库中一样,索引的维护总是伴随着附加成本。变更集合的每一个操作(比如创建、更新或删除)都会带来开销,因为索引也需要被更新。为了维持一个最佳平衡,你需要定期检查使用一个索引的有效性,这可以通过你在系统上执行的读和写的比例来衡量。识别出较少使用的索引并且删除它们。

